Something occurred to me that, unfortunately, was just a little bit too big for a tweet, so I decided to blog instead, and add more context.
While thinking about the perennial question of whether static typing help reduce the number of bugs in an otherwise well tested code base, I was reminded of how many bugs I saw tagged by newer versions of Scala with improved static analysis and correctness, or how damn hard it is to do variance right when you start using it.
I was then struck by a thought: the "bugs" I was thinking of were not caught by tests because no feature in the code actually used the buggy class in a way that revealed the bug. This also relates to variance, because variance in Java is defined at the usage site, instead of definition site. The definitions are all invariant in Java (aside from arrays).
So, thinking about it, I came up with the following hypothesis:
Dynamically typed language proponents consider "bugs" to be things that the user of the software can cause it to do, while statically typed language proponents consider "bugs" to be things that users of the code can cause it to do.
That would certainly account for some differences in attitude and beliefs I perceive. On the other hand, it might just be my imagination.
Tuesday, December 11, 2012
Monday, October 8, 2012
In hindsight, maybe I should have used Actors...
Postmortem
This post is meant for myself.
For the past six weeks, I have been working hard on a system target exclusively at the election day this past Sunday, October 7th 2012, in my country. Granted that I took off a few days to go to Agile Brazil 2012, but I returned every one of them with plenty interest.
So I write this for myself, as a postmortem, to help me clear up some ideas about it all. You see, this was the first time I had the opportunity to use Scala for anything critical -- or, for that matter, larger than a script -- as part of my job.
So, seriously, you don't have to read this. I'm sure there's some other post or presentation about Scala that's bound to be way more interesting than this, and which you haven't seen yet. Look up Scala Days, Skills Matter or NE Scala, if you are out of ideas. :-)
The Setting
Since you are still with me, I suppose I should explain a bit what the program was intended to do. It should help me figure out how within the scope everything turned out as well.
For a critical project, I'm a bit ashamed to admit it was nothing more than an ETL - Extract, Transform and Load. It was supposed to download election data, extract relevant information, and load it into a database. A few qualities deemed to be paramount:
- Resilience. The program should be able to withstand processing errors such as invalid data, connectivity problems and such. Depending on the kind of error, it would either retry or ignore -- but always log!
- Reliability. If the program deemed a particularly process to be successfully concluded, it damn well better be both error free and finished. That was harder than it sounds, which is something I should look into.
- Real Time. This program would feed systems used to provide news feeds on the election, so the sooner it got news out, the better. There was actually a software provided to do the extraction part in batch, which set up the bar for us.
- Resource Aware. This was a vague requirement, and not everyone thought it was a requirement at all. The point was being able to use lots of resources to extract data, but without going overboard and somehow get throttled down.
Highlights
Before I go any further on the real meat -- the problems -- I want to highlight the things that really shined, in my opinion.
Dispatch
This was the first time I used this controversial Scala library -- scala.io.Source had sufficed for me before. I understand the current generation, 0.9.x, has some important differences from previous ones. It has a much reduced set of operators, and it has full support for operator-free use. Also, it's asynchronous, which is were the fun came.
Let me be plain: Dispatch is awesome., and that has nothing to do with operators. Sure, the clean syntax is nice, though sometimes I'd prefer it had better support for tuple varargs. But that's just a side show. No, the main game is its asynchronous nature, and how it got implemented.
Dispatch is based on Async HTTP Client, which provides a nice layer over Java's asynchronous I/O libraries. And, of course, Dispatch provides a Scala layer over Async HTTP, making it even nicer. It does not, however hide Async HTTP. On the contrary, you work with Async HTTP objects at all times, and have the Dispatch abstractions available as enhancements.
Now, doing I/O asynchronously means you make a requisition and tell the library what it should do with it once the requisition is done, instead of waiting for the result and then doing stuff with it. That's what you see with NodeJS callbacks, for instance, and anyone who worked long enough with it should be at least wary of its traps.
The abstraction provided by Dispatch to work around that is called Promise, though it better approaches what Scala 2.10 will introduce as Future. Nope, that's not the old actor-based Future -- it's actually something that everyone has been doing (such as Dispatch), and which prompted it's inclusion in the library. See Scala Improvement Process 14 for more details. No, really, see it.
The gist of it (Dispatch-style) is that you are waiting for something to be completed (like the HTTP request you made), and you are holding onto an object, the promise, that will get it to you once it's finished. If an exception is thrown by the process, your program then the exception will be encapsulated into that promise as well. Extract it, and the exception is thrown at the point you extracted it. And, of course, Scala-style, you can map (or flatMap that shit) the results as you wish.
There's one thing I like better on Dispatch's Promise than Scala's Future is that it provides methods to convert the Promise[T] into a Promise[Option[T]] or Promise[Either[Throwable, T]], which makes error handling nice. I don't understand why Scala's Future doesn't have these simple interfaces. Option seems to require at least a one liner through andThen and toOption on a Try, but getting an Either out seems even harder. On Dispath, promise.either returns a promise for Either, and promise.Option returns a promise for Option, and that's that.
Dispatch also has something to convert an iterable of promises into a promise of iterables. Happily, Scala 2.10 has that as well, and even more.
So, anyway, all this meant it was very easy to chain transformations triggered by HTTP requests, logging errors were it made sense, flattening unsuccessful computations into None, and getting Either to code that could make sense out of it.
Performance and concurrency, easily understandable, easy to manipulate, FTW.
Specs2
I had some pretty tough challenges testing everything. Most of the code was written TDD, but there were plenty XMLs, JSONs, timing issues, concurrency issues, a dozen mostly similar classes that had to be tested for its small differences, etc. It's not that it was hard, though the wrong framework certainly could have made it so, but it made for some pretty gruesome tests, and one wants tests to be as easy to understand as possible.
Time and time again, Specs2 came through with the goods. I had used Specs2 before a few times already, but, interestingly enough, most of the features I was most familiar with (parser combinator testers, given-when-then combinators) were completely absent from my tests. To make up for it, I feel like I have seen everything that I had overlooked up to now. I know that's not true, because I have a list, you see, but...
I'm not claiming Specs2 does anything other frameworks don't -- the same way I didn't know Specs2 features I came to use, I don't know how well other frameworks handle them. I'm just saying that there wasn't a single thing I needed that couldn't be done with it, and in a very satisfactory manner.
A special mention goes to Mockito, a great mocking framework made greater by how well Specs2 is integrated with it.
Eric Torreborre
Eric's Specs2 author. The level of support he provided me was amazing, and anyone who spends sometime reading specs2 mailing list will know that's how he treats everyone. Did you find a bug, or needed something just a tiny little bit different than what Specs2 provides? It's rare the day I don't see Eric rolling out a new snapshot with it within 24 hours, tops.
Do you have trouble understanding how to make your tests work a certain way, or how to do something in Specs2? Eric will discuss it until you come away enlightened.
I've always been a bit amazed at Eric's awesomeness, but having it while writing a critical piece of software made it really personal. So, thanks Eric.
Unfiltered
Unfiltered is a cousin (maybe a brother) to Dispatch, handling the other end of HTTP requests. What's nice about Unfiltered is that it works as a library, making it really easy to add small HTTP servers to your code. This wasn't part of the production code, but it made testing the parts of the code that did HTTP requests really easy.
I have no basis to make recommendations on it as a general library (though it certainly bears investigation), but I heartily endorse it to handle those interface (as in, with other systems) tests. It was doubly useful to me, since both my Input and my Output (the database I was feeding) were HTTP servers.
AVSL and Grizzled SLF4J
These nice libraries by Brian Clapper made the logging goes smoothly. It was particularly striking given that some other modules of the project got a lot of trouble on this regard.
Anyway, I picked AVSL as a suggestion from Dispatch, which uses SLF4J-based logging. Knowing I could replace AVSL had a soothing effect, and it was pretty easy to get working quickly. I started out with an AVSL-only logging to handle some immediate problems I was having, and then replaced them with Grizzled to be able to replace AVSL if needed.
AVSL was easy to configure and use, and it was particularly nice being able to get extra verbose logging on some parts of my code while keeping the rest relatively quiet when I tried to figure out why something wasn't working as I expected it to.
IntelliJ IDEA
On the first week, I worked solely with Sublime Text 2, since that was the editor of preference of the person I was pairing with. Given that he didn't have Scala experience, I thought it was fair to have anything else I could as familiar as possible to him.
Then he moved on to some other part of the project that was demanding some urgent attention, and I was left finishing up the project (until the scope changed, that is).
Now, I'm a vim user, and happily so, but I came up upon some issues that demanded heavy refactoring, and so I turned to IntelliJ. I wish IntelliJ did more -- Scala support pales in comparison to Java's -- but the final result would have looked a lot uglier than it is if not for IntelliJ.
I bought a personal license for it at the start of the third week, as I geared up to start working on the nodejs module. That never happened, but I don't regret spending that money.
TDD
So, I arrived 9:20 am on Sunday to do the first load of static data for the election ("static" data could, and did, change at any time to account for judicial decisions). I ran the code and got some database insertion errors. Now, I had had some trouble with the database during stress tests, but this didn't look like the problems we had, and there certainly wasn't any stress going on.
So I investigated the problem, found the cause in some badly formatted input, changed the code to account for it, produced a new snapshot, tested it, and put it in production. I didn't ask for permission, I didn't talk to my colleages to hear what they thought about it, I just did it, not only without fear, but with absolute confidence I didn't break anything with that change. On the morning of the election day.
I've seen plenty of last minute changes throughout my career, mind you, but I might even take a bet on that more than half of them broke something else. Changing with confidence that nothing broke -- without breaking things! -- is something I have only known through TDD.
That was hardly the only time I got benefits out of TDD, but it serves to epitomize my whole experience. The scope changed on us many times, and I had to do fundamental changes to my code as result, but nothing that was working before ever stopped working.
Of course, I did introduce a few bugs despite TDD, though they were usually very short lived.
Elastic Search Head (boring link, but follow to the github link)
This is an HTML5 application that serves as a general interface/console to the Elastic Search database. You can just clone the repository and open your browser on it's index.html to use it -- there are no additional requirements.
I cannot imagine ever working with Elastic Search without it, but, then again, there's absolutely no reason why should that ever happen -- it's free, and the only requisite is an HTML5 enabled browser. If you have an Elastic Search you interact with, get this.
Furthermore, I'm now very unhappy with everything else for not having something like it. Well, maybe they have and I have lived in the dark ages so far. Now that I have seen the light, though, I have some pretty high standards concerning what kind of tooling should be freely available to a database of any kind.
Elastic Search itself is responsible for it to a great extent -- like this, there are many other tools available for it.
Bumps
Naturally, there were parts of the project that, while providing value overall, were besmirched by some problems. Now, the following stuff provided overall net gains for the project, but I'm going to concentrate on what was difficult, as that's the places were improvements can be made.
SBT
You knew I was going to say that, don't you?
SBT is a major source of love-hate relationships. I mostly like it, and get confused why people seem to have so much trouble with it. It seems to come down to multi-module projects (that is, not using an internal repository to handle separate projects as separate projects), and plugins (and why do people need to do so much weird stuff anyway?). Well... it could stand to be more discoverable. Things like "show scala-version" vs "set scalaVersion" also get in the way, and, to further make this point, I still don't get exactly why it has to be this way.
But none of this was a problem to me. This was a single module project, with a build.sbt and a project/plugins.sbt, and that was that. Setting things up was a simple matter of copy&paste from library and sbt plugins. So, no, knowing what lines to put in these files never presented any problem.
My problem was getting SBT to run at all. Being a Scala geek, I've been writing my sbt shell scripts for a long time now, downloading launcher jars and stuff like that, but what worked for me on my own free time was simply not good enough to get such a critical project going.
Simply put, people who were not me and didn't really understand much of Scala, let alone SBT, had to be able to build and test the project, with minimal instructions. Fortunately, the SBT site now has nice Debian packages for download. Only it doesn't, really -- it has a package that installs a source for the SBT package, and it turns out that I manage my sources automatically through Puppet, which made that very annoying. I had to install the package to find out what the source was so I could put it on the build server configuration.
Only that didn't really help. You see, I use SBT 0.12 since about the time it came out, and that's not the version available on the site above. Worse, some of the global plugins I have are incompatible with the version provided by the Debian package.
The problems didn't stop there, however. The developers machine need to go out through an NTLM authenticated proxy with Basic Authentication as fallback. Unix tools in general and Java in particular seems to have a lot of trouble with this setup. Browsers have no problem whatsoever, but getting SBT to download itself (the parts that are not the launcher) takes some doing. Using the proxy, yes, that's easy. Getting it to authenticate, now, there's a challenge.
In the end, I ended bundling SBT 0.12's jar, a hand crafted sbt shell script, and some obscure configuration options to make it download everything from our Artifactory. That meant adding every single dependency to it, and some of those dependencies -- like those of typesafe -- were tough to get right. Lots of trouble with ivy2 repos vs maven repos, and lots of maven repos were I had to tell Artifactory not to validate the poms.
Once all of that was ready, the rest was a breeze. After all the trouble I had, I delayed doing the Jenkins build for a long time, only to get it working the first time in less than ten minutes when i finally got to it. Code coverage reports, code duplication, style checks, source code x-ray, javadocs, single jar files, generation of ensime project for Sublime2, generation of IntelliJ and Eclipse projects... Almost all of it accomplished effortlessly.
Also, sbt ~test worked really well during the time I used Sublime Text 2, but I suppose that isn't a surprise to anyone. Or, at least, I sure hope so.
SCCT
This is the tool I used to generate code coverage. It mostly works, but I doubted it for a while. You see, you have to compile the whole project (or, perhaps, all of the tests) with its action for it to work. If it uses partial compilation on something, it only shows coverage for those files that were changed!
Once I figured that, it was a simple thing to add a clean to the Jenkins project, or when running on my own machine. Since I only look at code coverage sporadically, this wasn't a problem. There was no need for integration on Jenkins, so Jenkins build times were not a problem either. If they were, it would be pretty easy to separate normal testing from full artifact generation.
So, what do I mean by "mostly"? It displays abstract classes and traits as untested, and it really bothers me to see all those 0% where there isn't any code to be tested to begin with. Also, it marks literal constants (that is, untyped final vals on objects) as untested. That's fair enough, and I suppose it can't be helped unless you get the compiler to do some instrumentation for you.
As for the rest, everything works, and it integrates nicely with Jenkins.
Scala X-Ray (Browse)
I don't know why I had so much trouble setting this up. I expect I assumed it could only be an SBT plugin, so all the instructions I found didn't make any sense at all. Once I realized it is a compiler plugin and just added the two lines indicated by the site above to my build.sbt, it worked. But I did spend a lot of time trying to figure it out, and didn't even get it working on the first time.
Elastic Search
After a brief flertation with some other solutions, we settled on Elastic Search as the data store. It was not exactly what we wanted, but there wasn't much time to explore solutions. ES was something I was mildly familiar with, and given that most of the project was written in Javascript, interacting with ES was really easy. It also benefited from Dispatch on the Scala side.
Unfortunately, the actual load we put on it was very different from what we expected. We expected lots of reads, few updates, but actually got something the other way around, and that caused performance issues (on stress tests only, though -- normal loads were fine).
Also, it's log didn't help much when we started having problems. In the end, it turned out that one of the tools we were using to monitor it, BigDesk, was actually causing it to crash. We stopped using it, and, aside from it not being capable of handling the stress test loads, it worked fine otherwise.
It's HTTP/JSON interface really did help get everything working easily, and it's data model, while targetted at uses rather different than ours, worked fine for us.
The Ugly Parts
I can't honestly point to anything and say that was a a major problem. The closest thing to that would be the changes in scope with progressively tighter deadlines (it's not like election day could be postponed, after all), but that comes with the job, and it's our responsibility to deal with it the best we can.
Some problems resulting from ill-conceived solutions to the new requisites marred the end result, but the alternative to have something that didn't work well would have been not having anything. The original scope was fully delivered, and worked with a single hitch.
In Hindsight
So, what I learned from all that?
I'd like to start with some lessons about Scala. I wonder what's the maturity level displayed by my code... There are no type classes, just two implicit declarations, and hardly any of the more complex you may have seen me write here and elsewhere. There's not a fold to be seen anywhere.
And, yet, it's mostly functional. There are some thing I wished to make immutable, but I couldn't figure out how to handle the concurrency requirements in a functional manner. There are a few places were I knew a way to make something immutable, but did not choose to do so, and ended up regretting it. And, yet, it looks -- to me -- pretty normal.
Maybe I'm wearing blinders. There are certainly plenty maps and a few flatMaps, which couldn't really be otherwise given the role Dispatch plays in it. But, to me, the code looks downright tame. That surprised me a lot, given the code size.
Very few case classes, but just perfect when I needed them. Some sealed traits and objects which could have been replaced by a decent enumeration (but do have a small advantage). One implicit conversion to a tuple so that I could use the unzip method, and some other place I needed to make an Ordering type implicit to get around the fact it isn't contra-variant.
Named and default parameters were put to very good use -- I wish Scala would let me get away with using named when interfacing with Java. It might not be able to check the parameter name, reorder parameters, and there's certainly no defaults, but method calls with booleans and primitives feel just naked without the parameter name.
Test code was another matter -- Specs2 brings plenty of magic to the table, but it's a standard magic so to speak, which makes it possible for people who don't understand it to use it by rote.
So, what about actors? Given my experience with Scala and the concurrent nature of my problem, you might have wondered why I didn't use actors to solve it. And, if that didn't occur to you naturally, the title of this post should certainly have done so!
It's... complicated. The original scope didn't look like it would benefit from using actors, and I still think so. As I originally envisioned it, a main thread would start Dispatch downloads, and the mappings done to the Promise returned by them would handle everything else. Nothing would ever be returned to the main thread. A single semaphore would put a hard limit on how many simultaneous downloads would be allowed, and the main thread would sleep until the time for more downloads came.
In that scenario, using actors would just add overhead. However, things changed. The first big change was that the interaction with the other modules would have to be batched. That's something I was never comfortable with, since it lost precious seconds gained by the ETL's architecture. But, most importantly, it meant information would have to go from the async download trigger threads to the main loop. At that point, we have a bi-directional conversation, which is were actors start getting interesting.
Still, the interaction was very simple, and none of the more sophisticated interactions enabled by actors would be of any use. As things progressed, however, that changed, as the contents of some downloads started dictating the need for other downloads, which could trigger other downloads, and failing any one of those downloads should dictate the outcome for the ones that triggered them.
And now you have a complex net of interactions, some of which would benefit from let-it-fail and corresponding recovery mechanisms. It now looks like a perfect fit for actors.
So, the code I wrote does handle almost every error condition, and with some refactoring it could have handled all of them. However, what started out natural and intuitive has become confusing. If I had used a simple actor setup right from the start, bare bones as it would have been, I could have pursued better solutions as the requirements changed.
The other, more troubling, consideration is that, given the batching limitation imposed upstream from my system, maybe we should have gone with the standard downloader and a bare bones extraction&load script.
In Conclusion
Overall, I don't regret any of the technical choices I made. Surely a second version would benefit from hindsight (and be vulnerable to the second version syndrome), but the choices I made proved equal to the task, and quite adequate to withstand the changing requisites and short deadline.
As a side note, this project could have gone with Ruby just as likely as with Scala, and it was just a coincidence that pushed it to Scala. I wonder how that would have turned out, and it is an experience I'd have loved to have.
And if you have read it all and think it was a waste of time, don't say I didn't warn you! :-)
Sunday, September 2, 2012
Bugs, TDD and Functional Programming
I'm watching a BBC series produced long ago called "The Machine That Changed The World". At some point, Mitch Kapor (founder of Lotus) says, as the narrator compares building software to building airplanes, buildings and bridges:
So if you've got something that's not holding its weight well, you look toI see both TDD and functional programming as ways to change that.
see if the the joint is tight, or if the screws are right. You don't have to
go and analyze the whole building. Well, software doesn't work like that. If
you see a problem when you attempt to execute a certain command, there is no
simple and direct way of knowing which part of the code could have the problem.
In some sense it could be almost anywhere. And so the detective problem of
hunting down the source of the problem is enormously harder than in physical
media because the digital media don't obey the same simplifying law of
proximity of cause and effect.
For TDD, it's quite obvious, and, in fact, one of the benefits lauded by proponents of the practice. If some bug shows up (in the test), then it must be related to the change you just made. Since changes are supposed to be small if you do it right, then the code path you must follow to find the bug should be quite restricted.
The same holds for functional programming, with the advantage of applying to bugs that did not show up on the tests. A program in functional programming is supposed to be a composition of functions, and each function should be referentially transparent -- side-effect free, so that it's output relies solely on the input, and pure, so that it always return the same output for a given input. So, once you can reproduce the problem -- one you have an input that causes the bug -- you can go down the functions that handle it and see if they are returning the correct output for the input they are receiving.
Add both together, and software starts looking a lot more like building an airplane or a bridge. In this respect, anyway.
When I left work for the weekend on Friday, I had just started feeding input from another module of the systems we are building, as my own module finally got to the point one could start doing integration tests. There is a bug: some data I expected to be produced isn't showing up.
As it happens, however, the code that looks at that data is functional and was developed using TDD. If it got the input I expected, it would have returned the output I wanted. That means when I arrive at work tomorrow, I'll look at the input being provided, and I know it will not be the same as the input the system was tested with. I'll see what's different, and, knowing that, I'll be able to tell exactly which piece of code should have handled it, and find out why it isn't doing what's supposed to do.
It really beats the alternative.
Saturday, August 25, 2012
JSON serialization with reflection in Scala! Part 2
An Apology
First off, I'd like to apologize to all for taking so long to follow up on my last post. Believe it or not, I only posted that one once this one was written, but... I waited for a couple of bugs to be fixed, and then the API changed, and there were new bugs, and so on. Even as I write this, with 2.10.0-M7 out and a good likelihood of it being followed by RC1, I still uncovered a Blocker bug on reflection!
Anyway, I wanted to avoid teaching people things that would turn out not to be true, and, so, I delayed. I think it's time, now to go ahead with this post. As soon as I finish this preamble, I'll revise the post and the code, and I hope to catch all problems. If you find anything amiss, please notify me that I can fix it the sooner!
A Warning
I'm writing this with 2.10.0 ready but not yet announced, and I've just became aware that, at the moment, reflection is not thread-safe. See issue 6240 for up-to-date information.
Recap
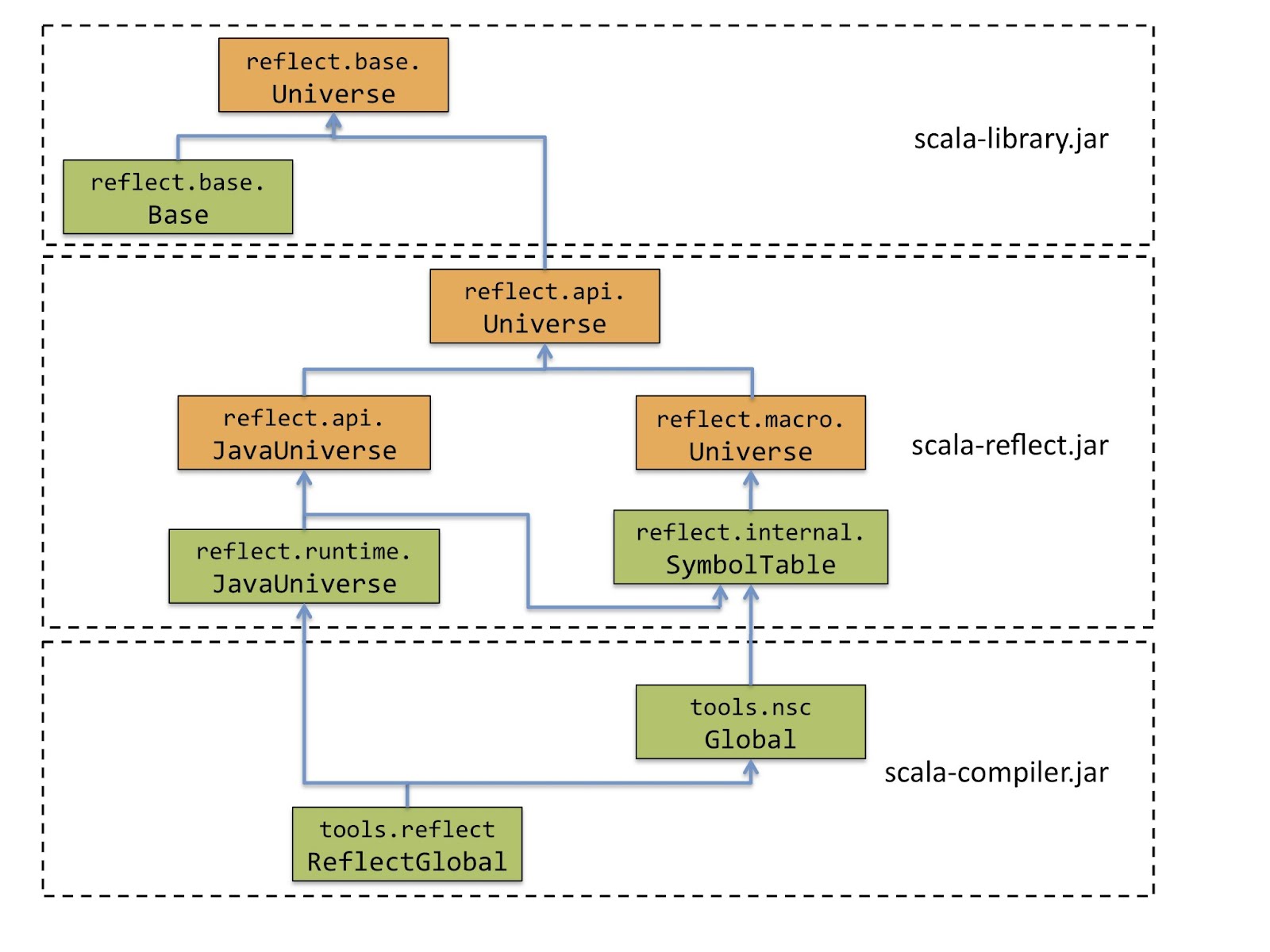
We saw on part 1 that Scala 2.10 will have a reflection library, and baited you into reading all post with the promise of a serializer written with it. That library is divided into layers through the cake pattern, which is used to provide increasingly more detailed levels from very basic reflection all the way to what the compiler needs. Those layers are called Universes.
We saw the base and runtime Universe, and we looked at some code which made use of them. We did not, however, go into any detail about what's inside these layers, and how those things relate to each other, and how to manipulate them.
So get ready, because we are getting into that right now!
What's in a Universe?
Reflection is available at different layers, and layers are Universes, so what's in a Universe? Quite a lot, actually. I invite anyone to look at the inheritance list of a typical universe, such as scala.reflect.runtime.JavaUniverse. Now look at scala.reflect.api.JavaUniverse, which is the type you actually see when you use scala.reflect.runtime.universe, and see how much smaller it is. That will make you feel better about how much stuff is still in there. :-)
A Universe has pretty much every kind of member one can have in Scala: type, trait, class, object, val, lazy val, def... I haven't seen a var, fortunately. But I can't guarantee there isn't one either! There is so much stuff in them that browsing will look like a daunting activity. But there's some logic to what's in there, which I'd like to go into before we get into actual details.
The core of Universe are its type members. The type type members are usually defined as boundaries, which enable the different layers to make them different things while still exposing a rich API. There are also classes and traits declaring those APIs or implementing them.
One pattern you'll see often enough is a type X, with a trait XApi, and possibly a class XBase. The logic is the following: X is used in the declarations of methods, and it is sometimes declared as a type with upper and lower bounds. The traits by the name XApi, often used as upper bounds on X, refer to declarations on scala.reflect.api, the full fledged reflection provided by scala-reflect.jar. XBase refers to things declared at scala.reflect.base, the minimal implementation provided on the standard library.
You'll often see class XExtractor as well. That contains apply and unapply methods which enables its instances to be used to create instances of X, or pattern match them. For each XExtractor, you'll find a val X with type XExtractor. On scala.reflect.api, classes will usually be abstract class. Elsewhere, you may find concrete implementations.
And speaking of value members, beside those extractors I just mentioned, you'll often see YTag, which are constants for ClassTag, and are used to preserve identities of abstract types from erasure, so that pattern matching works correctly. Sometimes you'll also see YTpe, Type constants, which expose core types.
There are few methods. Their main use seems to be creating new stuff, though some of them find stuff through implicit values (most prominently, typeOf). There's also some helper methods, to let you interactively discover what you have.
Let's start with the first one. Anything you define in Scala has a Symbol. If you give something a name, then it has a Symbol associated with it. If you didn't give it a name, but you could have, then it has a Symbol.
A Symbol has a Name, a Type, an owner (from which one can extract some other relationships, such as enclosing method, class and package), possibly a companion, and some flags with a bunch of information about it. Of particular relevance inside the compiler, a Symbol is mutable (see method setFlags). However, at run time it is immutable.
I'll skip briefly ahead and talk about Name. Scala has two namespaces: values and types. So a single String can refer to different things according to the namespace. All names, however, are either TermName (values) or TypeName (types), which makes it possible to use a Name anywhere required without having to specify to which namespace that name belongs.
That's why, for example, I did not have to say I was looking for a value member called head, instead of a type member of that name, in the example on part 1.
Names also abstract their representation on a classfile, where they have to be encoded to be considered valid identifiers.
Type is where most of the reflective action is, in my opinion. A type is not, say, Int -- that's just its Symbol (assuming we are talking about scala.Int, and not just the name). A Type is the information about all members that compose that thing: methods, fields, type parameters, nested classes and traits, etc. If a Symbol represents a definition, a Type represents the whole structure of that definition. It is the union of all definitions that compose a class, the description of what goes into a method and what comes out, etc.
Some types are simpler than others, of course. On the example at part 1, we looked at the three types that can represent a method. Other types, such as those for traits and classes, will inevitably be much more complex. We saw that too, as we searched inside the type intMethods received, looking for the methods we wanted.
And, because Type can be so many different things, you'll often have to pattern match against a specific subclass of Type, or its extractor, also as seen on that example. Types are immutable, though note that, inside the compiler, the symbols it contains are mutable.
A Tree is the compiler's internal representation for source code. It is what is usually called an Abstract Syntax Tree, or AST. A Tree, like Type, is composed of many different subclasses, which together represent everything that has semantic meaning on Scala source code.
Like names, a Tree can be of a Type (TypTree -- sic), or of non-types (TermTree). Either way, it is further broken down into subclasses.
Trees have children (other trees), a Position (pos), a Type (tpe) and a Symbol (symbol), though the latter might be null.
Tree is immutable at run time as well, but one can set symbols, types and positions are compile time, with macro's universe. We'll look more at trees when we discuss macros.
The remaining concepts are not important to the task at hand, so I'll not go into them. I'd like to draw attention, however, to StandardDefinitions, which is a superclass of JavaUniverse, and, therefore, directly available through it, DefinitionsApi, which is available through the method definitions on the previous trait. Together, they contain many symbols and types for things that are fundamental to the Scala language.
A Universe has pretty much every kind of member one can have in Scala: type, trait, class, object, val, lazy val, def... I haven't seen a var, fortunately. But I can't guarantee there isn't one either! There is so much stuff in them that browsing will look like a daunting activity. But there's some logic to what's in there, which I'd like to go into before we get into actual details.
The core of Universe are its type members. The type type members are usually defined as boundaries, which enable the different layers to make them different things while still exposing a rich API. There are also classes and traits declaring those APIs or implementing them.
One pattern you'll see often enough is a type X, with a trait XApi, and possibly a class XBase. The logic is the following: X is used in the declarations of methods, and it is sometimes declared as a type with upper and lower bounds. The traits by the name XApi, often used as upper bounds on X, refer to declarations on scala.reflect.api, the full fledged reflection provided by scala-reflect.jar. XBase refers to things declared at scala.reflect.base, the minimal implementation provided on the standard library.
You'll often see class XExtractor as well. That contains apply and unapply methods which enables its instances to be used to create instances of X, or pattern match them. For each XExtractor, you'll find a val X with type XExtractor. On scala.reflect.api, classes will usually be abstract class. Elsewhere, you may find concrete implementations.
And speaking of value members, beside those extractors I just mentioned, you'll often see YTag, which are constants for ClassTag, and are used to preserve identities of abstract types from erasure, so that pattern matching works correctly. Sometimes you'll also see YTpe, Type constants, which expose core types.
There are few methods. Their main use seems to be creating new stuff, though some of them find stuff through implicit values (most prominently, typeOf). There's also some helper methods, to let you interactively discover what you have.
Basic Concepts: What's X?
Ok, there's a lot of X in there, and, to be honest, I don't know much about them. However, most of them are subtypes of one of a few main concepts, or repetitions following the type/api/base pattern I mentioned above. I'll quote again from Scala Reflect Pre-SIP, linked to their definitions on scala.reflect.api.JavaUniverse:
| Name | Description |
|---|---|
| Symbol | Types representing definitions |
| Type | Types representing types |
| Tree | Types representing abstract syntax trees |
| Name | Types representing term- and type-names |
| AnnotationInfo | Types representing annotations |
| Position | Types representing positions of tree nodes in source files |
| FlagSet | Type representing sets of flags that apply to symbols and definition trees |
| Constant | Type representing compile-time constants |
Let's start with the first one. Anything you define in Scala has a Symbol. If you give something a name, then it has a Symbol associated with it. If you didn't give it a name, but you could have, then it has a Symbol.
A Symbol has a Name, a Type, an owner (from which one can extract some other relationships, such as enclosing method, class and package), possibly a companion, and some flags with a bunch of information about it. Of particular relevance inside the compiler, a Symbol is mutable (see method setFlags). However, at run time it is immutable.
I'll skip briefly ahead and talk about Name. Scala has two namespaces: values and types. So a single String can refer to different things according to the namespace. All names, however, are either TermName (values) or TypeName (types), which makes it possible to use a Name anywhere required without having to specify to which namespace that name belongs.
That's why, for example, I did not have to say I was looking for a value member called head, instead of a type member of that name, in the example on part 1.
Names also abstract their representation on a classfile, where they have to be encoded to be considered valid identifiers.
Type is where most of the reflective action is, in my opinion. A type is not, say, Int -- that's just its Symbol (assuming we are talking about scala.Int, and not just the name). A Type is the information about all members that compose that thing: methods, fields, type parameters, nested classes and traits, etc. If a Symbol represents a definition, a Type represents the whole structure of that definition. It is the union of all definitions that compose a class, the description of what goes into a method and what comes out, etc.
Some types are simpler than others, of course. On the example at part 1, we looked at the three types that can represent a method. Other types, such as those for traits and classes, will inevitably be much more complex. We saw that too, as we searched inside the type intMethods received, looking for the methods we wanted.
And, because Type can be so many different things, you'll often have to pattern match against a specific subclass of Type, or its extractor, also as seen on that example. Types are immutable, though note that, inside the compiler, the symbols it contains are mutable.
A Tree is the compiler's internal representation for source code. It is what is usually called an Abstract Syntax Tree, or AST. A Tree, like Type, is composed of many different subclasses, which together represent everything that has semantic meaning on Scala source code.
Like names, a Tree can be of a Type (TypTree -- sic), or of non-types (TermTree). Either way, it is further broken down into subclasses.
Trees have children (other trees), a Position (pos), a Type (tpe) and a Symbol (symbol), though the latter might be null.
Tree is immutable at run time as well, but one can set symbols, types and positions are compile time, with macro's universe. We'll look more at trees when we discuss macros.
The remaining concepts are not important to the task at hand, so I'll not go into them. I'd like to draw attention, however, to StandardDefinitions, which is a superclass of JavaUniverse, and, therefore, directly available through it, DefinitionsApi, which is available through the method definitions on the previous trait. Together, they contain many symbols and types for things that are fundamental to the Scala language.
The Serializer
Let's start writing that serializer, then. First, I'd like to make clear the following:
- This serialization is not comprehensive.
- This serialization is not correct (no edge cases treated, like quotes inside strings).
- I'm making no claims on its speed.
- THIS IS NOT PRODUCTION CODE.
So, what will this serializer handle? I'm planning on the following:
- Strings (without handling required escaping).
- AnyVal (without bothering with correcting Char or Unit).
- Any class whose constructor parameters are preserved as fields.
For the remainder of this post, I assume you have this import:
import scala.reflect.runtime.universe._
The signature for my serializer is this:
def serialize[T : TypeTag](obj: T): String
TypeTag deserves an explanation. A TypeTag is a type class which allows us to retrieve a Type. That is, it provides the Type equivalent of the getClass method, but through a type class pattern. Its implicit can be used by typeOf to retrieve the Type.
However, a TypeTag is not just a container for Type. It brings an Universe and a Mirror with it, and the latter is associated with class loaders (a TypeTag allows the creation of a Type on any mirror -- we'll look at mirrors later). That means, while getting a Type from a TypeTag is easy, getting a TypeTag needs more than just a Type.
With all that in mind, let's proceed.
However, a TypeTag is not just a container for Type. It brings an Universe and a Mirror with it, and the latter is associated with class loaders (a TypeTag allows the creation of a Type on any mirror -- we'll look at mirrors later). That means, while getting a Type from a TypeTag is easy, getting a TypeTag needs more than just a Type.
With all that in mind, let's proceed.
Values and Strings
We start with values and strings, which are the easiest ones to handle if we don't treat special cases. If obj is either a value (a descendant of AnyVal), just output its string representation. If it's a String, output it between double quotes.
We just have to compare types. Given a TypeTag, I can use typeOf on abstract types to get their Type. We an also call typeOf on AnyVal, but there's a pre-defined constants for it which we'll make use of. So, for now, this is what we have:
val objType = typeOf[T] if (objType <:< typeOf[String]) s""""$obj"""" else if (objType <:< definitions.AnyValTpe) obj.toString else "Unknown"
I'm going to refactor this code further on, so I'm not writing the full body of the method for now. Next, let's do collections. To handle them, I need to recurse, and that causes a problem... we can get the Type for the type parameter of a collection, but, as we saw, getting a TypeTag from a Type is hard.
Since we don't really need a TypeTag anywhere, we'll create a nested method to recurse on, and pass Type explicitly everywhere.
To gather all collections in one step, we'll compare them against GenTraversable, but that causes another trouble for us. We cannot write typeOf[GenTraversable], without a type parameter, nor do we have a known type parameter to put there. Even if we were to retrieve the type parameter of objType -- which might not exist in first place -- we cannot insert it on our source code. We'll have to do something else instead, to get at that type parameter.
There's a method on Type which help us here. The method baseType on Type return a new Type that corresponds to the symbol passed to it if that Type is an ancestor of the first type. Ok, that's confusing as hell, so let's explain it with code:
I hope that's clearer now. You might have expected using baseType with Set and Seq to return Iterable, but that's the "least upper bound", available through the lub helper method on universes.
All we need now is to try to find a baseType, and, if we didn't get a NoType back, we have a collection and we can recurse on it, producing a JSON array. Here's all of it, with the new inner recursion method:
That's pretty neat as far as it goes, -- and please notice the pattern matching used to extract the type parameter from GenTraversable -- but there are some issues with it. For instance, if the static type of the collection is something like List[Any], the elements we recurse into will be serialized as Unknown. If this seems like a small penalty, consider that any ADT will be represented by its top-most class. So, for instance, if I have a List[Tree] where Tree can be either the case class Node or the case class Leaf, we'll not be able to break it into nodes and leafs: we'll only see Tree.
One possibility to correct that is to go from the object's Class to its Type, taking advantage of the fact that we can always know the former at run time. This might lead to the opposite problem, where we serialize classes that are not meant to be visible. That would happen with List's subclass ::, for example, if the collection check did not catch it. But, since we are learning here, let's do it.
Before we do so, however, we need to talk about mirrors...
Sorry, I had to get that pun out. You probably know how Java reflection works: we have handles representing classes, methods, fields, etc. You then call methods on these handles to get other handles and, finally, you pass an instance to a method on one of these handles to act upon that instance. For example, from Class you get Method, and on Method you call invoke passing an instance to execute it.
Now, there are some problems with that, but I'm not the person to argue them. I refer you to Reflecting Scala by Yohann Coppel (PDF), and to Coppel's own main reference, Gilad Bracha's Mirrors: Design Principles for Meta-level Facilities of. Object-Oriented Programming Languages (PDF).
I'll concentrate on what they are and how you use them. From Reflection Pre-SIP, a mirror defines a hierarchy of symbols starting with the root package _root_ and provides methods to locate and define classes and singleton objects in that hierarchy.
Each universe may have one or more mirrors, and each mirror is tied to a Class Loader. This latter point is very important, because class loaders may load different classes with the same name. Of note, as well, class loaders may delegate to each other, so finding a class may involve doing the same search through a chain of class loaders.
Mirrors mostly abstract all this away, but, as a consequence, they are tied to class loaders, which means you must reflect through a mirror that knows the class of that instance.
There's a default mirror that will usually work, scala.reflect.runtime.currentMirror. That will use the class loader of the class that invokes it to create the mirror, which will usually be ok, but I'll avoid using it. Instead, I'll use a method provided by the universe to create a new mirror based on the class loader for the class of the instance. It goes like this:
That's pretty straight-forward, and, I, at least, got used to it pretty quickly. I had a bit of resistance at first, but knowing it will always get the right classloader makes me feel more confident.
Now that we saw two distinct ways of getting a Mirror, let's talk about how we use it. Mirrors are supposed to reflect the language, and not its compile time representation. Each instance, class, field, method and module (packages or singleton objects) is reflected through a corresponding mirror.
Through these mirrors we can act on the things they mirror. Note, however, that you do not pass the instance to these mirrors: you generate a mirror for the instance (an InstanceMirror), and, from there, you can get mirror to its methods, fields and class. You can also get a ClassMirror without an instance, but you won't be able to do much more than get a mirror for the constructor or its companion object.
Let's put that in another way. A MethodMirror is associated not only with a method, but with a method on a specific instance. You don't pass an instance to it to invoke the method, you just invoke it.
Since we don't really need a TypeTag anywhere, we'll create a nested method to recurse on, and pass Type explicitly everywhere.
To gather all collections in one step, we'll compare them against GenTraversable, but that causes another trouble for us. We cannot write typeOf[GenTraversable], without a type parameter, nor do we have a known type parameter to put there. Even if we were to retrieve the type parameter of objType -- which might not exist in first place -- we cannot insert it on our source code. We'll have to do something else instead, to get at that type parameter.
There's a method on Type which help us here. The method baseType on Type return a new Type that corresponds to the symbol passed to it if that Type is an ancestor of the first type. Ok, that's confusing as hell, so let's explain it with code:
scala> typeOf[List[Int]].baseType(typeOf[Seq[Int]].typeSymbol) res26: reflect.runtime.universe.Type = Seq[Int] scala> typeOf[List[Int]].baseType(typeOf[Seq[_]].typeSymbol) res27: reflect.runtime.universe.Type = Seq[Int] scala> typeOf[List[Int]].baseType(typeOf[Seq[String]].typeSymbol) res28: reflect.runtime.universe.Type = Seq[Int] scala> typeOf[Set[Int]].baseType(typeOf[Seq[Int]].typeSymbol) // Set is not <:< Seq res29: reflect.runtime.universe.Type = <notype> scala> typeOf[Seq[Int]].baseType(typeOf[List[Int]].typeSymbol) // Seq is not <:< List res30: reflect.runtime.universe.Type = <notype> scala> typeOf[Seq[Int]].baseType(typeOf[List[Int]].typeSymbol) == NoType res31: Boolean = true scala> typeOf[Seq[String]].typeSymbol // Symbols do not have type parameters res32: reflect.runtime.universe.Symbol = trait Seq
I hope that's clearer now. You might have expected using baseType with Set and Seq to return Iterable, but that's the "least upper bound", available through the lub helper method on universes.
All we need now is to try to find a baseType, and, if we didn't get a NoType back, we have a collection and we can recurse on it, producing a JSON array. Here's all of it, with the new inner recursion method:
import scala.collection.GenTraversable
def serialize[T : TypeTag](obj: T): String = {
def recurse(obj: Any, objType: Type): String = {
if (objType <:< typeOf[String]) s""""$obj""""
else if (objType <:< definitions.AnyValTpe) obj.toString
else if (objType.baseType(typeOf[GenTraversable[_]].typeSymbol) != NoType) {
val refinedType = objType.baseType(typeOf[GenTraversable[_]].typeSymbol)
val TypeRef(_, _, argumentType :: Nil) = refinedType
val objAsColl = obj.asInstanceOf[GenTraversable[_]]
val recursedSeq = objAsColl map (recurse(_, argumentType))
recursedSeq.mkString("[ ", ", ", " ]")
} else "Unknown"
}
recurse(obj, typeOf[T])
}
That's pretty neat as far as it goes, -- and please notice the pattern matching used to extract the type parameter from GenTraversable -- but there are some issues with it. For instance, if the static type of the collection is something like List[Any], the elements we recurse into will be serialized as Unknown. If this seems like a small penalty, consider that any ADT will be represented by its top-most class. So, for instance, if I have a List[Tree] where Tree can be either the case class Node or the case class Leaf, we'll not be able to break it into nodes and leafs: we'll only see Tree.
One possibility to correct that is to go from the object's Class to its Type, taking advantage of the fact that we can always know the former at run time. This might lead to the opposite problem, where we serialize classes that are not meant to be visible. That would happen with List's subclass ::, for example, if the collection check did not catch it. But, since we are learning here, let's do it.
Before we do so, however, we need to talk about mirrors...
Mirror Images
What better way to get a reflection than use a mirror?Sorry, I had to get that pun out. You probably know how Java reflection works: we have handles representing classes, methods, fields, etc. You then call methods on these handles to get other handles and, finally, you pass an instance to a method on one of these handles to act upon that instance. For example, from Class you get Method, and on Method you call invoke passing an instance to execute it.
Now, there are some problems with that, but I'm not the person to argue them. I refer you to Reflecting Scala by Yohann Coppel (PDF), and to Coppel's own main reference, Gilad Bracha's Mirrors: Design Principles for Meta-level Facilities of. Object-Oriented Programming Languages (PDF).
I'll concentrate on what they are and how you use them. From Reflection Pre-SIP, a mirror defines a hierarchy of symbols starting with the root package _root_ and provides methods to locate and define classes and singleton objects in that hierarchy.
Each universe may have one or more mirrors, and each mirror is tied to a Class Loader. This latter point is very important, because class loaders may load different classes with the same name. Of note, as well, class loaders may delegate to each other, so finding a class may involve doing the same search through a chain of class loaders.
Mirrors mostly abstract all this away, but, as a consequence, they are tied to class loaders, which means you must reflect through a mirror that knows the class of that instance.
There's a default mirror that will usually work, scala.reflect.runtime.currentMirror. That will use the class loader of the class that invokes it to create the mirror, which will usually be ok, but I'll avoid using it. Instead, I'll use a method provided by the universe to create a new mirror based on the class loader for the class of the instance. It goes like this:
runtimeMirror(obj.getClass.getClassLoader)
That's pretty straight-forward, and, I, at least, got used to it pretty quickly. I had a bit of resistance at first, but knowing it will always get the right classloader makes me feel more confident.
Now that we saw two distinct ways of getting a Mirror, let's talk about how we use it. Mirrors are supposed to reflect the language, and not its compile time representation. Each instance, class, field, method and module (packages or singleton objects) is reflected through a corresponding mirror.
Through these mirrors we can act on the things they mirror. Note, however, that you do not pass the instance to these mirrors: you generate a mirror for the instance (an InstanceMirror), and, from there, you can get mirror to its methods, fields and class. You can also get a ClassMirror without an instance, but you won't be able to do much more than get a mirror for the constructor or its companion object.
Let's put that in another way. A MethodMirror is associated not only with a method, but with a method on a specific instance. You don't pass an instance to it to invoke the method, you just invoke it.
Of Mirrors and Types
So, to put it all together, to invoke a method on an instance through reflection you need to:
val obj = "String"
val objClass = obj.getClass
val classClassLoader = objClass.getClassLoader
val classLoaderMirror = runtimeMirror(classClassLoader)
val classSymbol = classLoaderMirror.classSymbol(objClass)
val classType = classSymbol.typeSignature
val methodName = newTermName("length")
val methodSymbol = classType.member(methodName).asMethod
val instanceMirror = classLoaderMirror.reflect(obj)
val methodMirror = instanceMirror.reflectMethod(methodSymbol)
methodMirror.apply() // == (obj.length: Any)
Got all that? That, of course, assumes we know that there is a method named length on the thing we are reflecting about. If that we not the case, we would get a nasty surprise when we tried to retrieve the method's symbol.
More importantly right now, we also saw how we go from an instance to that instance's type, though we loose any type parameters along the way (or, more precisely, they are abstract).
More importantly right now, we also saw how we go from an instance to that instance's type, though we loose any type parameters along the way (or, more precisely, they are abstract).
Untagged Serialization
Let's then rewrite what we had before, but without TypeTag.
import scala.collection.GenTraversable
def serialize(obj: Any): String = {
val mirror = runtimeMirror(obj.getClass.getClassLoader)
val objType = mirror.classSymbol(obj.getClass).typeSignature
val StringTpe = mirror.classSymbol(classOf[String]).typeSignature
if (objType <:< StringTpe) s""""$obj""""
else if (objType <:< definitions.AnyValTpe) obj.toString // DOES NOT WORK!!!
else if (objType.baseType(typeOf[GenTraversable[_]].typeSymbol) != NoType) {
val refinedType = objType.baseType(typeOf[GenTraversable[_]].typeSymbol)
val TypeRef(_, _, argumentType :: Nil) = refinedType
val objAsColl = obj.asInstanceOf[GenTraversable[_]]
val recursedSeq = objAsColl map serialize
recursedSeq.mkString("[ ", ", ", " ]")
} else "Unknown"
}
Anyway, there's one big problem there, right? Because we are coming from Java reflection, comparing to AnyVal doesn't work at all. We can compare against the value types themselves, such as Int, but it won't work here because any Int we find with this method will be boxed, and Integer is not a subtype of Int.
So while we gained something, we lost the ability of handling AnyVal easily. What to do?
End of Part 2
What a perfect cliffhanger!
Hopefully, someone will tell me what to do before part 3 comes out, and it will look like I know what I am doing! :-)
More seriously, we have covered a lot of ground already. Whatever path we take from here will tread on familiar ground, just enriching what we have seen so far a bit more, making the code more elaborate. Until we get to macros, anyway.
This is a good place to stop and consider what we have seen so far.
Scala 2.10 will come with a reflection library. That library is built with the cake pattern on layers, so that code common to standard library, reflection library and compiler gets shared. It also keeps the reflection library in sync with the compiler, and makes the reflection more faithful to the language.
The reflection layers are called Universes, and there are a few of them to choose from. A Universe contains APIs and implementations for a number of interrelated concepts. We saw the most important ones, and used Symbol, Type and Name quite a bit. We also saw a bit of TypeTag, which replaces Manifest on Scala 2.10 (yeah, I know -- I didn't tell you that before).
We were then surprised with the news that there was something else to learn about: mirrors! It turns out we can't actually do anything without a mirror to an instance, a class, a method or whatever. Mirrors are tied to class loaders, which introduces some complications and a little bit of ceremony, but they aren't really that hard to use.
Empowered with our newly gained knowledge, we proceeded to tack the serialization problem in two different ways, with mixed results.
At that point we were left in a major cliffhanger: What path to take? Is there a way around the problems? And what about macros?
Rest assured, because this is to be continued...
Hopefully, someone will tell me what to do before part 3 comes out, and it will look like I know what I am doing! :-)
More seriously, we have covered a lot of ground already. Whatever path we take from here will tread on familiar ground, just enriching what we have seen so far a bit more, making the code more elaborate. Until we get to macros, anyway.
This is a good place to stop and consider what we have seen so far.
Scala 2.10 will come with a reflection library. That library is built with the cake pattern on layers, so that code common to standard library, reflection library and compiler gets shared. It also keeps the reflection library in sync with the compiler, and makes the reflection more faithful to the language.
The reflection layers are called Universes, and there are a few of them to choose from. A Universe contains APIs and implementations for a number of interrelated concepts. We saw the most important ones, and used Symbol, Type and Name quite a bit. We also saw a bit of TypeTag, which replaces Manifest on Scala 2.10 (yeah, I know -- I didn't tell you that before).
We were then surprised with the news that there was something else to learn about: mirrors! It turns out we can't actually do anything without a mirror to an instance, a class, a method or whatever. Mirrors are tied to class loaders, which introduces some complications and a little bit of ceremony, but they aren't really that hard to use.
Empowered with our newly gained knowledge, we proceeded to tack the serialization problem in two different ways, with mixed results.
At that point we were left in a major cliffhanger: What path to take? Is there a way around the problems? And what about macros?
Rest assured, because this is to be continued...
Epilogue
While I waited and waited and waited, Alois Cochard wrote Sherpa, a macro-based serialization toolkit. I'm guessing one can learn a lot by looking at its source code!
Tuesday, July 3, 2012
JSON serialization with reflection in Scala! Part 1
So you want to do reflection?
Scala 2.10 will come with a Scala reflection library. I don't know how it fares when it comes to reflecting Java -- I'll look into it when I have time. For now, my hands are overflowing with all there is to learn about scala.reflect.So, first warning: this is not an easy library to learn. You may gather some recipes to do common stuff, but to understand what's going on is going to take some effort. Hopefully, by the time you read this Scaladoc will have been improved enough to make the task easier. Right now, however, you'll often come upon types which are neither hyperlinked, nor have path information on mouse-over, so it is important to learn where you are likely to find them.
It will also help to explore this thing from the REPL. Many times as I worked my way towards enlightenment (not quite there yet!), I found myself calling methods on the REPL just to see what type it returned. At other times, however, I stumbled upon exceptions where I expected none! As it happens, class loaders play a role when reflecting Scala -- and REPL has two different mirrors.
There's also a difference between classes loaded from class files versus classes that have been compiled in memory. Scala stores information about the type from Scala's point of view in the class file. In its absence (REPL-created classes), not all of it can be recomposed.
Bottom line: having the the code type check correctly is not a guarantee of success, when it comes to reflection. Even if the code compiles, if you did not make sure you have the proper mirror, it will throw an exception at run time.
In this blog post, I'll try to teach reflection basics, while building a small JSON serializer using Scala reflection. I'll also go, in future posts, through a deserializer and a serializer that takes advantage of macros to avoid slow reflection calls. I'm not sure I'll succeed, but, if I fail, maybe someone will learn from my errors and succeed where I failed.
As a final note: don't trust me! I'm learning this stuff as I go, and, besides, it isn't set into stone yet. Some of what you'll see below is already scheduled to be changed, other things might change as result of feedback from the community. But every piece of code will be runnable on the version I'm using -- which is something between Scala 2.10.0-M4 and whatever comes next. I'm told, even as I write this, that Scala 2.10.0-M5 is around the corner, and it will provide functionality I'm missing, and fix bugs I've stumbled upon.
Warning: I'm writing this with 2.10.0 ready but not yet announced, and I've just became aware that, at the moment, reflection is not thread-safe. See issue 6240 for up-to-date information.
The Reflection Libraries
When Martin Odersky decided to write Scala's reflection library, he stumbled upon a problem: to do reflection right -- that is, to accomplish everything reflection is supposed to accomplish -- he'd need a significant part of the compiler code duplicated in the standard library.The natural solution, of course, would be moving that code to the standard library. That was not an enticing prospect. It happened before, with some code related to the XML support, and the result speaks for itself: the standard library gets polluted with code that makes little sense outside the compiler, and the compiler loses flexibility to change without breaking the standard library API. As time passes, code would start to be duplicated so it could be changed and diverge, and the code in the standard library would become useless and rot.
So, what to do? Odersky found the solution in a famous Scala pattern: the cake pattern. Scala reflection is a giant multi-layered cake. We call these layers universes, and in them we find types, classes, traits, objects, definitions and extractors for various things. A simple look at what the base universe extends gives us a notion of what's in it: Symbols with Types with FlagSets with Scopes with Names with Trees with Constants with AnnotationInfos with Positions with TypeTags with TagInterop with StandardDefinitions with StandardNames with BuildUtils with Mirrors.
The base layers provides a simple API, with type members defined by upper bounds where minimal functionality is provided. That base layer is available in the standard library, shared by all users of reflection API: scala.reflect.base.Universe. This provides replacements for the now deprecated Manifest and ClassManifest used elsewhere in the standard library, and also serves as a minimally functional implementation of reflection, available even when scala-reflect.jar is not referenced.
The standard library also has a bare bones implementation of that layer, through the class scala.reflect.base.Base, an instance of which is provided as scala.reflect.basis, in the scala.reflect package object.
Take a moment and go over that again, because it's a common pattern on the reflection library. The instance basis is a lazy val of type Universe, whose value is an instance of class Base.
Upon this layer we can find other layers that enrich that API, providing additional functionality. Two such layers can be found on a separate jar file, scala-reflect.jar. There's a base API on package scala.reflect.api, which is also called Universe. This API is inherited by the two implementations present in this jar: the java-based runtime scala.reflect.api.JavaUniverse, and scala.makro.Universe, used by macros. By the way, the name of this last package will change, at which point this link will break. If I do not fix it, please remind me in the comments.
Now, notice that these are APIs, interfaces. The actual implementation for scala.reflect.api.JavaUniverse is scala.reflect.runtime.JavaUniverse, available through the lazy val scala.reflect.runtime.universe (whose type is scala.reflect.api.JavaUniverse).
At any rate, the JavaUniverse exposes functionality that goes through Java reflection to accomplish some things. Not that it is limited by Java reflection, since the compiler can inject some information at compile time, and keeps more precise type information stored on class files. You'll see how far it can go in the example.
There are more layers available in the compiler jar, but that's beyond our scope, and more likely to change with time. Look at the image below, from the Reflection pre-SIP for an idea of how these layers are structured.
What's it for, anyway?
So, what do we do with a reflection library? If you think of Java reflection, you'll end up with a rather stunted view of what reflection should do, given how limited it is. In truth, Java reflection doesn't even reflect the Java language, which is a much more limited language than Scala.
The Scala Reflection pre-SIP suggests some possibilities, though not all are contemplated by what's available on Scala 2.10.0:
- Runtime reflection where one explores runtime types and their members, and gains reflective access to data and method invocations.
- Reification where types and abstract syntax trees are made available at runtime.
- Macros which use reflection at compile time to access their context and produce trees and types.
It goes on to describe some questions that must be answered by the reflection library:
- What are the members of a certain kind in a type?
- What are the types of these members as seen from an instance type?
- What are the base classes of a type and at which instance types are they inherited?
- Is some type is a subtype of another?
- Among overloaded alternatives of a method, which one best matches a list of argument types?
That doesn't mean we can open a class and rewrite the code in its methods -- though macros might allow that at some point after 2.10.0. For one thing, bytecode doesn't preserve enough information to reconstruct the source code or even the abstract syntax tree (the compiler representation of the code).
A class file contains a certain amount of information about the type of a class, and an instance of a class just knows what its own class is. So, if all you have is an instance, you can't gain knowledge through reflection about the type parameters it might have. You can, however, use that information at compile time through macros, or preserve it as values for use at run time.
Likewise, though you cannot recover the AST (abstract syntax tree) of a method, but you can get the AST for code at compile time, modify it with macros, or even parse, compile and execute code at run time if you use what's available on scala-compiler.jar.
Speaking of macros, I'd like to point out the suggestion that "reflection" might be used at compile time. Reflection is usually defined as a run time activity. However, the API used by macros (or the compiler) at compile time will be mostly the same as the one used by programs at run time. I predict Scala programmers will unassumingly talk about "reflection at compile time".
Speaking of macros, I'd like to point out the suggestion that "reflection" might be used at compile time. Reflection is usually defined as a run time activity. However, the API used by macros (or the compiler) at compile time will be mostly the same as the one used by programs at run time. I predict Scala programmers will unassumingly talk about "reflection at compile time".
"This is all getting a little confusing..."
Ok, so let's see some code to show you what I'm talking about. I'm not going to call methods or create instances, since that requires more information than we have seen so far, and, besides, you could do that stuff with Java reflection already.
Let's start with a simple example. We'll get the type of a List[Int], search for the method head, and then look at its type:
scala> import scala.reflect.runtime.universe._
import scala.reflect.runtime.universe._
scala> typeOf[List[Int]]
res0: reflect.runtime.universe.Type = List[Int]
scala> res0.member(newTermName("head"))
res1: reflect.runtime.universe.Symbol = method head
scala> res1.typeSignature
res2: reflect.runtime.universe.Type = => A
The initial import made the runtime universe, the one that makes use of java reflection, available to us. We then got the the type we wanted with typeOf, which is similar to classOf. After that, we got a handle to the method named head, and, from that handle (a Symbol), we got a Type again.
Note that the type being returned by the method is "A". It has not been erased, but, on the other hand, is not what we expected from List[Int]. What we got was the true type of head, not the type it has on a List[Int]. Alas, we can do the latter quite easily:
scala> res1.typeSignatureIn(res0) res3: reflect.runtime.universe.Type = => Int
Which is what we expected. But, now, let's make things a bit more general. Say we are given a instance of something whose static type we know (that is, it isn't typed Any or something like that), and we want to return all non-private methods it has whose return type is Int. Let's see how it goes:
scala> def intMethods[T : TypeTag](v: T) = {
| val IntType = typeOf[Int]
| val vType = typeOf[T]
| val methods = vType.members.collect {
| case m: MethodSymbol if !m.isPrivate => m -> m.typeSignatureIn(vType)
| }
| methods collect {
| case (m, mt @ NullaryMethodType(IntType)) => m -> mt
| case (m, mt @ MethodType(_, IntType)) => m -> mt
| case (m, mt @ PolyType(_, MethodType(_, IntType))) => m -> mt
| }
| }
intMethods: [T](v: T)(implicit evidence$1: reflect.runtime.universe.TypeTag[T])Iterable[(reflect.runtime.universe.MethodSymbol, reflect.runtime.universe.Type)]
scala> intMethods(List(1)) foreach println
(method lastIndexWhere,(p: Int => Boolean, end: Int)Int)
(method indexWhere,(p: Int => Boolean, from: Int)Int)
(method segmentLength,(p: Int => Boolean, from: Int)Int)
(method lengthCompare,(len: Int)Int)
(method last,=> Int)
(method count,(p: Int => Boolean)Int)
(method apply,(n: Int)Int)
(method length,=> Int)
(method hashCode,()Int)
(method lastIndexOfSlice,[B >: Int](that: scala.collection.GenSeq[B], end: Int)Int)
(method lastIndexOfSlice,[B >: Int](that: scala.collection.GenSeq[B])Int)
(method indexOfSlice,[B >: Int](that: scala.collection.GenSeq[B], from: Int)Int)
(method indexOfSlice,[B >: Int](that: scala.collection.GenSeq[B])Int)
(method size,=> Int)
(method lastIndexWhere,(p: Int => Boolean)Int)
(method lastIndexOf,[B >: Int](elem: B, end: Int)Int)
(method lastIndexOf,[B >: Int](elem: B)Int)
(method indexOf,[B >: Int](elem: B, from: Int)Int)
(method indexOf,[B >: Int](elem: B)Int)
(method indexWhere,(p: Int => Boolean)Int)
(method prefixLength,(p: Int => Boolean)Int)
(method head,=> Int)
(method max,[B >: Int](implicit cmp: Ordering[B])Int)
(method min,[B >: Int](implicit cmp: Ordering[B])Int)
(method ##,()Int)
(method productArity,=> Int)
scala> intMethods(("a", 1)) foreach println
(method hashCode,()Int)
(value _2,=> Int)
(method productArity,=> Int)
(method ##,()Int)
Please note the pattern matching above. Tree, Type and AnnotationInfo are ADTs, and often you'll need pattern matching to deconstruct or to obtain a more precise type. For the record, the pattern matches above refer to methods without parameter lists (like getters), normal methods, and methods with type parameters, respectively.
EDIT: A recent discussion indicates that pattern matching with types may not be reliable. Instead, the code above should have read like this:
def intMethods[T : TypeTag](v: T) = {
val IntType = typeOf[Int]
val vType = typeOf[T]
val methods = vType.members.collect {
case m: MethodSymbol if !m.isPrivate => m -> m.typeSignatureIn(vType)
}
methods collect {
case (m, mt @ NullaryMethodType(tpe)) if tpe =:= IntType => m -> mt
case (m, mt @ MethodType(_, tpe)) if tpe =:= IntType => m -> mt
case (m, mt @ PolyType(_, MethodType(_, tpe))) if tpe =:= IntType => m -> mt
}
}
I decided to put up this edit as quickly as possible, so I'm just posting the revised version of the method, instead of revising the post with usage, etc.
To finish up the examples, let's see some manipulation of code:
scala> import scala.tools.reflect.ToolBox
import scala.tools.reflect.ToolBox
scala> import scala.reflect.runtime.{currentMirror => m}
import scala.reflect.runtime.{currentMirror=>m}
scala> val tb = m.mkToolBox()
tb: scala.tools.reflect.ToolBox[reflect.runtime.universe.type] = scala.tools.reflect.ToolBoxFactory$ToolBoxImpl@5bbdee69
scala> val tree = tb.parseExpr("1 to 3 map (_+1)")
tree: tb.u.Tree = 1.to(3).map(((x$1) => x$1.$plus(1)))
scala> val eval = tb.runExpr(tree)
eval: Any = Vector(2, 3, 4)
That's code by Antoras, by the way, from this answer on Stack Overflow. While we do not go into any manipulation of the parsed code, we can actually decompose it into Tree sub-components, and manipulate it.
End of Part 1
There's still a lot to see! We have touched on some concepts like Type and Tree, but without going into any detail, and there was a lot going on under the covers. That will have to wait a bit, though, to keep these posts at manageable levels.
To recapitulate, Scala 2.10 will come with a Scala reflection library. That library is used by the compiler itself, but divided into layers through the cake pattern, so different users see different levels of detail, keeping jar sizes adequate to each one's use, and hopefully hiding unwanted detail.
The reflection library also integrates with the upcoming macro facilities, enabling enterprising coders to manipulate code at compile time.
We saw the base and runtime layers, mentioned a bit of other layers, then went into some reasons for wanting a reflection library, and some tasks such a library ought to be able to do.
Finally, we looked at bits of a REPL session, where we used the reflection library to find out information we could never have found through plain Java reflection. We also saw a bit of code that made parsing and running Scala code at run time pretty easy.
On part 2, we'll look at the main basic concepts of Scala Reflection's Universe, and how they relate to each other. We'll then proceed to the promised JSON serializer. We'll follow on this series with the deserializer, and end up by taking advantage of macros to avoid reflection at run time.
See you then!
Monday, January 23, 2012
String Interpolation on Scala 2.10
One of the Scala Improvement Proposals for Scala 2.10 is String Interpolation. It has recently been added to trunk, behind the -Xexperimental flag, and I have started playing with it. At first, I stumbled upon bugs and limitations of its current implementation relative to the proposal, but I finally got something working.
To be clear: the interpolation works fine, in both of the provided forms (with and without formatting). As usual with Scala, it's the possibility of replicating the functionality for my own purposes that gets me excited. I usually explain the whys and the hows of my code, but in this case a simple paste says it all, imho.
To be clear: the interpolation works fine, in both of the provided forms (with and without formatting). As usual with Scala, it's the possibility of replicating the functionality for my own purposes that gets me excited. I usually explain the whys and the hows of my code, but in this case a simple paste says it all, imho.
dcs@ayanami:~/github/scala (master)$ scala -Xexperimental
Welcome to Scala version 2.10.0.rdev-4232-2012-01-23-g9a20086 (Java HotSpot(TM) 64-Bit Server VM, Java 1.6.0_26).
Type in expressions to have them evaluated.
Type :help for more information.
scala> case class StringContext(parts: String*) {
| object matching {
| def unapplySeq(s: String): Option[Seq[String]] = {
| val re = (parts map ("\\Q" + _ + "\\E") mkString ("^", "(.*?)", "$")).r
| re findFirstMatchIn s map (_.subgroups)
| }
| }
| def s(args: Any*) = scala.StringContext(parts: _*).s(args: _*)
| }
defined class StringContext
scala> "23/01/2012" match { case matching"$day/$month/$year" => s"$month-$day-$year" }
res0: String = 01-23-2012
Monday, January 9, 2012
Adding methods to Scala Collections
I don't like getting much involved in these Scala flame wars, but this recent article left me a bit irked. At some point, the following statement is made:
Is this what the author wanted? No. He wanted too add a method that behaved like a normal collection method to something that isn't a collection. This is so crazy that, not surprisingly, people are misunderstanding him.
Now, one may come up and say that Scala does do that (add methods to stuff that are not collection), with String and Array. Yes, it does, and it does so by creating a completely new class with all these methods for each of them. Rest assured that if I create a completely new class for each one, I can add filterMap to String and Array too.
"it is impossible to insert a new method that behaves like a normal collection method. "
So, for the record, that is just not true. Here's an implementation for the filterMap method:
import scala.collection._
import generic.CanBuildFrom
import mutable.Builder
class FilterMap[A, C <: Seq[A]](xs: C with SeqLike[A, C]) {
def filterMap[B, That](f: A => Option[B])
(implicit cbf: CanBuildFrom[C, B, That]): That = {
val builder: Builder[B, That] = cbf()
xs foreach { x => val y = f(x); if (y.nonEmpty) builder += y.get }
builder.result()
}
}
implicit def toFilterMap[A, C <: Seq[A]](xs: C with SeqLike[A, C]): FilterMap[A, C] = new FilterMap[A, C](xs)
Is this what the author wanted? No. He wanted too add a method that behaved like a normal collection method to something that isn't a collection. This is so crazy that, not surprisingly, people are misunderstanding him.
Now, one may come up and say that Scala does do that (add methods to stuff that are not collection), with String and Array. Yes, it does, and it does so by creating a completely new class with all these methods for each of them. Rest assured that if I create a completely new class for each one, I can add filterMap to String and Array too.
Subscribe to:
Posts (Atom)

